Google Kembangkan Text-To-Image, Kini Kamu Bisa Desain Grafis Hanya Dengan Mengetik
![]() Akmal Choiron | Kamis, 16 Juni 2022
Akmal Choiron | Kamis, 16 Juni 2022
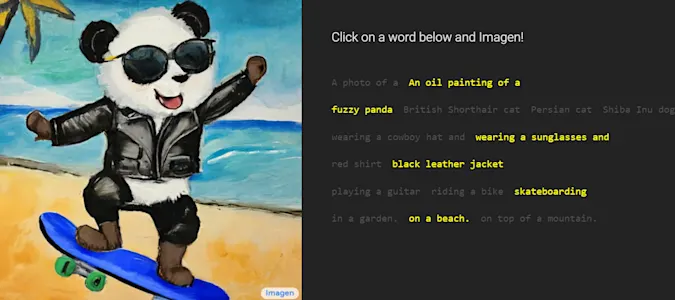
Minggu lalu para penggemar teknologi artificial intelligence atau kecerdasan buatan sedang ramai membahas perihal kabar terbaru dari perusahaan teknologi terbesar saat ini, Google, di mana perusahaan tersebut diketahui telah memamerkan sistem kecerdasan buatan baru yang dapat membuat gambar berdasarkan input teks. Model kecerdasan buatan yang diberi nama Imagen oleh Google ini merupakan model kecerdasan buatan yang dikembangkan oleh Brain Team di Google Research. Image saat ini menawarkan tingkat hasil penggambaran yang realistik yang belum pernah dikembangkan oleh perusahaan manapun sebelumnya dengan tingkat kecerdasan yang begitu luar biasa sehingga Imagen disebut memiliki tingkat pemahaman bahasa yang mendalam.
Secara official, keterangan yang disampaikan Google menyebutkan bahwa Imagen adalah model text-to-image yang mengaplikasikan prinsip-prinsip kecerdasan buatan. Pada dasarnya, Imagen merupakan sistem yang dapat membuat gambar fotorealistik dari teks input.
'Kami menghadirkan Imagen, sebuah sistem dengan model difusi teks-ke-gambar yang memiliki tingkat penggambaran paling realistik yang belum pernah terjadi sebelumnya dan tingkat pemahaman bahasa yang mendalam,' kata Google dalam informasi resminya. 'Imagen dibangun di atas kekuatan model pemahaman bahasa dengan transformator besar serta mendalam sehingga memiliki tingkat pemahaman teks tingkat tinggi dan bergantung pada kekuatan model difusi dalam pembuatan gambar dengan tingkat ketelitian tinggi.'
Saat ini Imagen belum tersedia untuk umum, tetapi Google telah membagikan informasi resmi mengenai beberapa contoh hasil kerja dari Imagen. Untuk proyek tersebut, Google memang sangat ketat dalam menerapkan standar tinggi, sehingga membuat tolak ukur yang komprehensif dan secara gamblang menyebutkan bahwa mereka lebih baik kualitasnya dibandingkan dengan kecerdasan buatan text-to-image lain yang ada di pasaran saat ini. Dengan keterangan ini, Google bisa dibilang telah memberanikan diri untuk bersaing dan membandingkan Imagen dengan metode AI lainnya seperti VQ-GAN+CLIP, Latent Diffusion Models, dan DALL-E 2. Mengacu pada hasil riset yang dilakukan oleh Google, disebutkan bahwa para responden lebih menyukai Imagen daripada para pesaing yang ada di pasaran saat ini.
Ketidaktersediaan Imagen untuk diakses masyarakat umum punya alasan tersendiri. Menurut Google "Dataset seperti ini sering mencerminkan stereotip sosial, sudut pandang yang menindas, dan asosiasi yang menghina, atau berbahaya, terhadap kelompok identitas yang terpinggirkan," tulis para peneliti. Imagen telah mewarisi "bias sosial dan keterbatasan model bahasa besar" dan mungkin menggambarkan "berbahaya stereotip dan representasi." Para peneliti dan pihak yang terlibat dalam Imagen diketahui telah mengatakan bahwa saat ini mereka berusaha untuk mengkodekan bias sosial, termasuk kecenderungan untuk membuat gambar orang dengan warna kulit lebih terang dan menempatkan mereka dalam peran gender stereotip tertentu ketika dimasukkan ke dalam sistem Imagen. Hal ini dilakukan karena Google khawatir bahwa sistem ini dapat disalahgunakan untuk membuat gambar yang tidak baik dengan tujuan secara sengaja menyebabkan kejahatan atau penghinaan.
Namun kabar baiknya, Google sendiri saat ini telah mengizinkan kita semua untuk bermain dengan model untuk menghasilkan gambar kita sendiri, tetapi para peneliti perlu mempertimbangkan kerangka kerja terlebih dahulu — tantangan itu sendiri

Image credit: Designboom.com

Image credit: Designboom.com
Sebenarnya Imagen bukanlah merupakan model kecerdasan buatan text-to-image yang pertama ditemui di pasaran. Beberapa model serupa juga dapat kita temui seperti misalnya DALL·E OpenAI (serta berbagai penerusnya) yang juga dapat melakukan text-to-image dengan sistem yang serupa. Namun, Imagen yang merupakan sistem text-to-image versi Google ini sebenarnya dikembangkan agar dapat menghasilkan kualitas gambar yang jauh lebih realistis dibandingkan dengan sistem kecerdasan buatan text-to-image lainnya. Selama pengembangan, para peneliti dari Google membuat tolak ukur atau standar yang sangat tinggi. Mereka bahkan meminta manusia untuk menilai setiap gambar yang dihasilkan dari berbagai input yang diberikan kepada sistem kecerdasan buatan Imagen. Diketahui bahwa para responden ini lebih memilih Imagen daripada model lain dalam perbandingan berdampingan, baik dalam hal kualitas sampel dan keselarasan gambar yang dihasilkan dengan teks yang dimasukkan.
Mengenai DALL-E, sistem kecerdasan buatan ini merupakan sistem kecerdasan buatan text-to-image yang dirilis oleh pengembang OpenAI pada April 2022 lalu. Sistem dari DALL-E sebenarnya jauh lebih sederhana daripada Imagen. Ditambah lagi, DALL-E lebih mirip seperti bot yang dapat membuat ilustrasi digital dalam berbagai gaya yang mengacu pada input berupa prompt teks sederhana. Saat ini DALL-E sebenarnya telah memiliki beberapa versi peniru atau copy cat nya.
Meskipun teknologi yang digunakan di balik DALL-E masih tetap terkunci dan menjadi rahasia pengembang sistem, tapi beberapa kompetitor mulai menggunakan nama DALL-E sebagai copy cat yang asli. Contohnya misalnya DALL-E Mini yang secara resmi tidak memiliki afiliasi dengan DALL-E versi Asli. DALL-E Mini ini adalah karya Boris Dayma, seseorang yang banyak diduga suka membuat tiruan dari suatu kecerdasan buatan (AI) agar lebih mudah diakses oleh semua orang secara gratis!. Hal ini diketahui dari laman sponsor yang dicantumkan oleh DALL-E Mini.
Sama seperti inspirasi versi aslinya, DALL-E Mini mampu menghasilkan citra asli dengan menggabungkan data dari database internet serta kata kunci dalam prompt teks.
Of the Author
Akmal Choiron
Anda mungkin juga tertarik
 IoT
IoT
Passwordless Future Kian Dekat, 1Password Bisa Jadi Pemotornya
Akmal Choiron | Jumat, 25 November 2022
 IoT
IoT
Aplikasi Ini Bantu Para Penderita Mental Illness Untuk Hidup Lebih Sehat
Akmal Choiron | Sabtu, 27 Agustus 2022
 IoT
IoT
Dyson Eye Robots, Robot Khusus Untuk Bantu Bereskan Pekerjaan Rumahmu yang Menumpuk
Akmal Choiron | Rabu, 22 Juni 2022